Read Header Row From Txt File Python
What is a stock-still width text file?
A fixed width file is like to a csv file, but rather than using a delimiter, each field has a set number of characters. This creates files with all the information tidily lined upward with an appearance similar to a spreadsheet when opened in a text editor. This is convenient if you're looking at raw information files in a text editor, but less ideal when yous demand to programmatically piece of work with the data.
Fixed width files have a few common quirks to continue in mind:
- When values don't eat the total character count for a field, a padding grapheme is used to bring the character count upwards to the total for that field.
- Any character tin be used as a padding character as long equally it is consistent throughout the file. White space is a mutual padding graphic symbol.
- Values can be left or correct aligned in a field and alignment must exist consistent for all fields in the file.
A thorough description of a fixed width file is available hither.
Annotation : All fields in a stock-still width file do non need to have the same character count. For example: in a file with three fields, the first field could be 6 characters, the second 20, and the concluding nine.
How to spot a fixed width text file?
Upon initial examination, a fixed width file can expect like a tab separated file when white infinite is used as the padding grapheme. If y'all're trying to read a stock-still width file every bit a csv or tsv and getting mangled results, endeavour opening it in a text editor. If the information all line up tidily, it's probably a stock-still width file. Many text editors also give grapheme counts for cursor placement, which makes it easier to spot a pattern in the character counts.
If your file is too large to easily open in a text editor, there are various means to sample portions of information technology into a separate, smaller file on the command line. An easy method on a Unix/Linux organisation is the caput command. The example beneath uses head with -n 50 to read the get-go fifty lines of large_file.txt and and so copy them into a new file called first_50_rows.txt.
caput -northward 50 large_file.txt > first_50_rows.txt Let's work with a existent life example file
UniProtKB Database
The UniProt Knowledgebase (UniProtKB) is a freely accessible and comprehensive database for protein sequence and annotation information bachelor under a CC-Past (iv.0) license. The Swiss-Prot branch of the UniProtKB has manually annotated and reviewed information about proteins for various organisms. Complete datasets from UniProt data tin can be downloaded from ftp.uniprot.org. The data for human being proteins are contained in a set of fixed width text files: humchr01.txt - humchr22.txt, humchrx.txt, and humchry.txt.
Nosotros don't need all 24 files for this example, and so here'south the link to the first file in the set up:
https://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/consummate/docs/humchr01.txt
Examine the file before reading it with pandas
A quick glance at the file in a text editor shows a substantial header that we don't need leading into 6 fields of data.
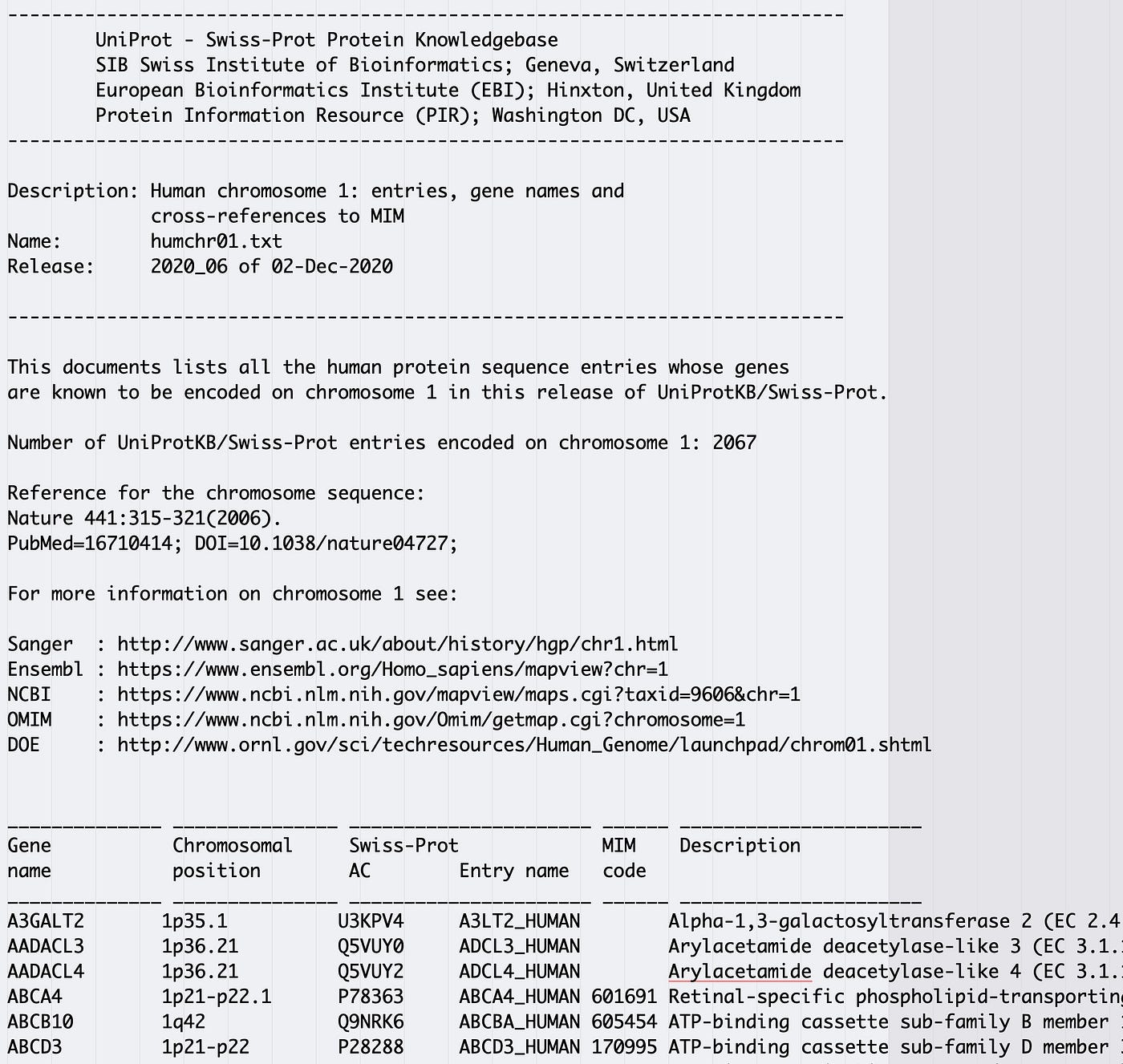
Fixed width files don't seem to be as common every bit many other data file formats and they can wait similar tab separated files at kickoff glance. Visual inspection of a text file in a expert text editor before trying to read a file with Pandas tin can substantially reduce frustration and assist highlight formatting patterns.
Using pandas.read_fwf() with default parameters
Note: All code for this example was written for Python3.6 and Pandas1.ii.0.
The documentation for pandas.read_fwf() lists v parameters:
filepath_or_buffer, colspecs, widths, infer_nrows, and **kwds
Two of the pandas.read_fwf() parameters, colspecs and infer_nrows, have default values that work to infer the columns based on a sampling of initial rows.
Let's utilize the default settings for pandas.read_fwf() to get our tidy DataFame. We'll leave the colspecs parameter to its default value of 'infer', which in turn utilizes the default value (100) of the infer_nrows parameter. These two defaults attempt to find a pattern in the first 100 rows of information (later on whatsoever skipped rows) and apply that blueprint to split the data into columns.
Basic file cleanup
At that place are several rows of file header that precede the tabular info in our instance file. Nosotros need to skip them when we read the file.
None of the parameters seem ideal for skipping rows when reading the file. So how do we do information technology? Nosotros utilize the **kwds parameter.
Conveniently, pandas.read_fwf() uses the same TextFileReader context manager as pandas.read_table(). This combined with the **kwds parameter allows us to use parameters for pandas.read_table() with pandas.read_fwf(). Then nosotros tin use the skiprows parameter to skip the first 35 rows in the instance file. Similarly, we can use the skipfooter parameter to skip the last 5 rows of the instance file that contain a footer that isn't role of the tabular information.
pandas.read_fwf('humchr01.txt', skiprows=35, skipfooter=v) The above try leaves the DataFrame a bit of a mess 😔:

Note: Since we're using the default values for colspecs and infer_nrows we don't have to declare them.
Part of the issue here is that the default colspecs parameter is trying to infer the cavalcade widths based on the outset 100 rows, simply the row right earlier the tabular data (row 36 in the file and shown in the column names above) doesn't really follow the character count patterns in the data table, and so the inferred column widths are getting mangled.
If we'd ready skiprows to 36 instead of 35, we'd accept concluded upwards with the first row of information pushed into the column names, which too mangles the inferred cavalcade widths. There'south no winning here without some boosted cleanup. Allow's settle the column names event with the names parameter and see if that helps.
Note: Using the names parameter means nosotros are not allocating a row in the file to column names, so nosotros as users take to make sure to account for the fact that skiprows must start at the first data row. So skiprows is set to 36 in the next example simply it was 35 in previous examples when we didn't apply the names parameter.
pandas.read_fwf('humchr01.txt', skiprows=36, skipfooter=5, names=['gene_name', 'chromosomal_position', 'uniprot', 'entry_name', 'mtm_code', 'description']) 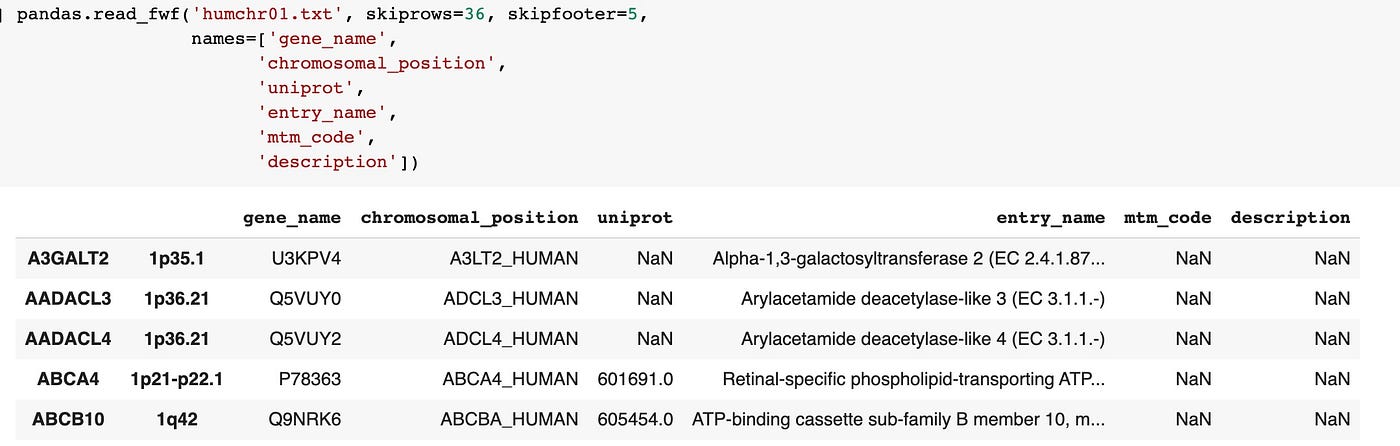
That's better, but still a bit of a mess. Pandas inferred the column splits correctly, only pushed the start two fields to the index. Permit'south set up the index issue past setting index_col=False.
pandas.read_fwf('humchr01.txt', skiprows=36, skipfooter=5, index_col=False, names=['gene_name', 'chromosomal_position', 'uniprot', 'entry_name', 'mtm_code', 'description']) 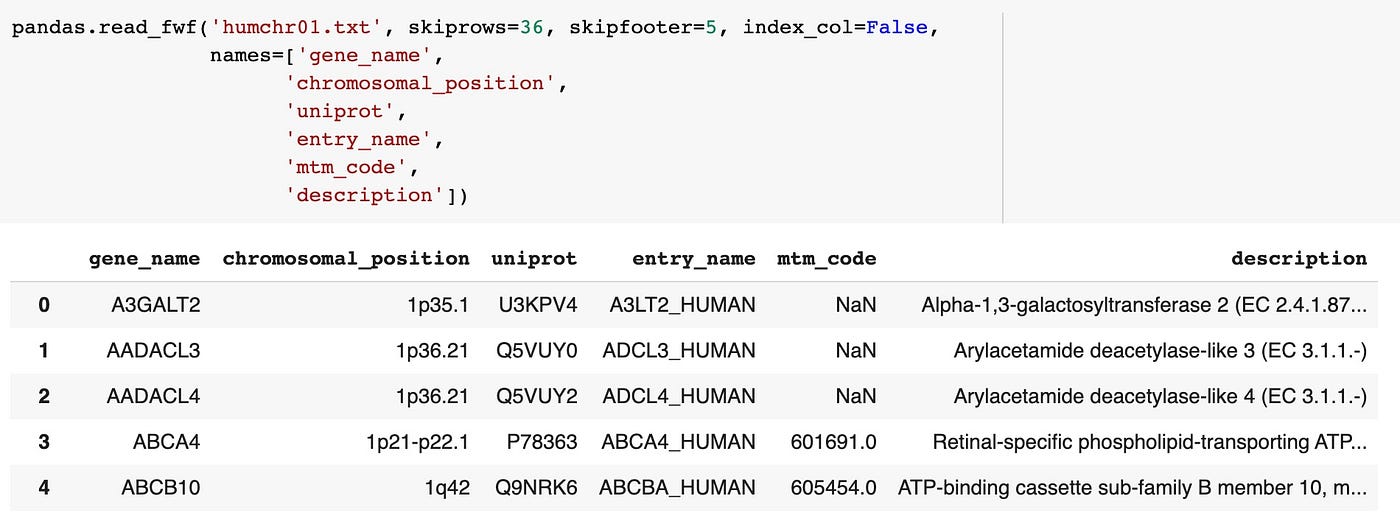
That looks expert! The columns are split correctly, the column names brand sense and the first row of data in the DataFrame matches the first row in the instance file.
Nosotros relied on the default settings for two of the pandas.read_fwf() specific parameters to get our tidy DataFame. The colspecs parameter was left to its default value of 'infer' which in plow utilizes the default value of the infer_nrows parameter and finds a pattern in the first 100 rows of data (after the skipped rows) and uses that to separate the data into columns. The default parameters worked well for this example file, just we could also specify the colspecs parameter instead of letting pandas infer the columns.
Setting field widths manually with colspecs
Only similar with the example above, we need to outset with some bones cleanup. We'll drop the header and footer in the file and set the column names just similar before.
The adjacent step is to build a list of tuples with the intervals of each field. The list below fits the instance file.
colspecs = [(0, fourteen), (14, 30), (30, 41), (41, 53), (53, 60), (60, -1)] Annotation the last tuple: (60, -1). We tin can utilise -i to indicate the last index value. Alternately, we could apply None instead of -1 to bespeak the last index value.
Annotation: When using colspecs the tuples don't take to exist exclusionary! The final columns tin exist set to tuples that overlap if that is desired. For instance, if you desire the commencement field duplicated: colspecs = [(0, xiv), (0, 14), ...
pandas.read_fwf('humchr01.txt', skiprows=36, skipfooter=five, colspecs=colspecs, names=['gene_name', 'chromosomal_position', 'uniprot', 'entry_name', 'mtm_code', 'description']) 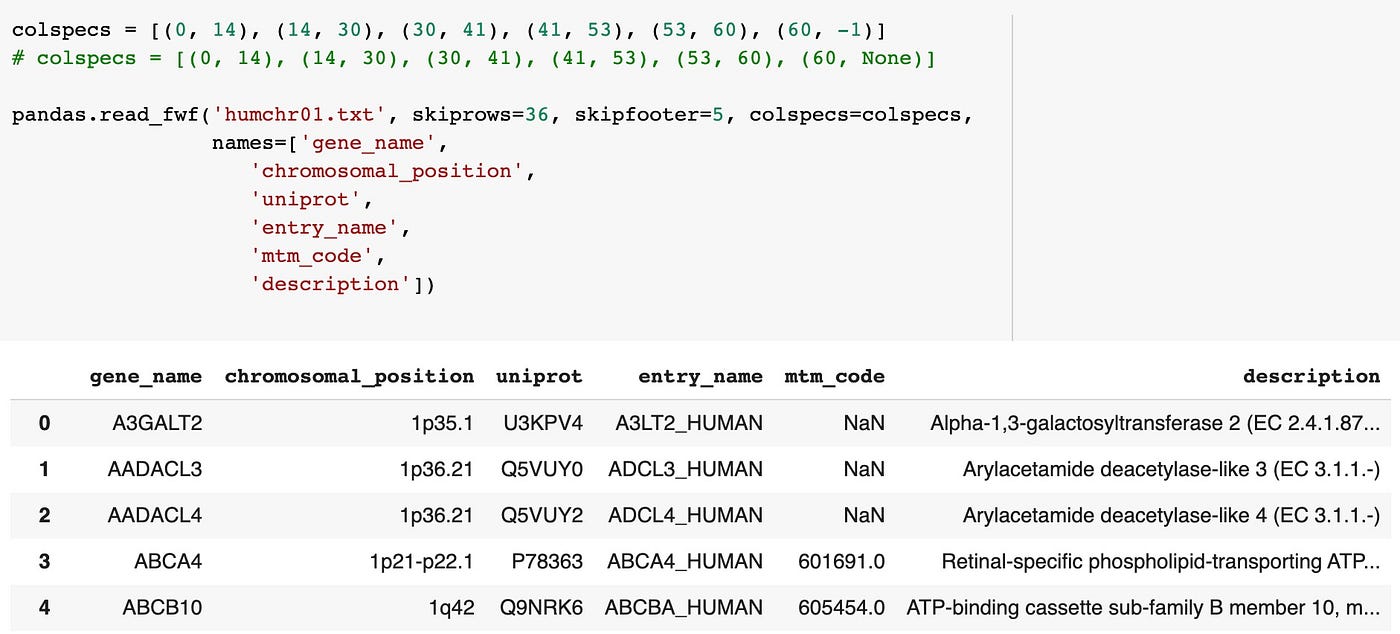
Once more nosotros've attained a tidy DataFrame. This time nosotros explicitly declared our field start and end positions using the colspecs parameter rather than letting pandas infer the fields.
Conclusion
Reading fixed width text files with Pandas is easy and accessible. The default parameters for pandas.read_fwf() work in most cases and the customization options are well documented. The Pandas library has many functions to read a variety of file types and the pandas.read_fwf() is one more useful Pandas tool to keep in mind.
Source: https://towardsdatascience.com/parsing-fixed-width-text-files-with-pandas-f1db8f737276
0 Response to "Read Header Row From Txt File Python"
Post a Comment